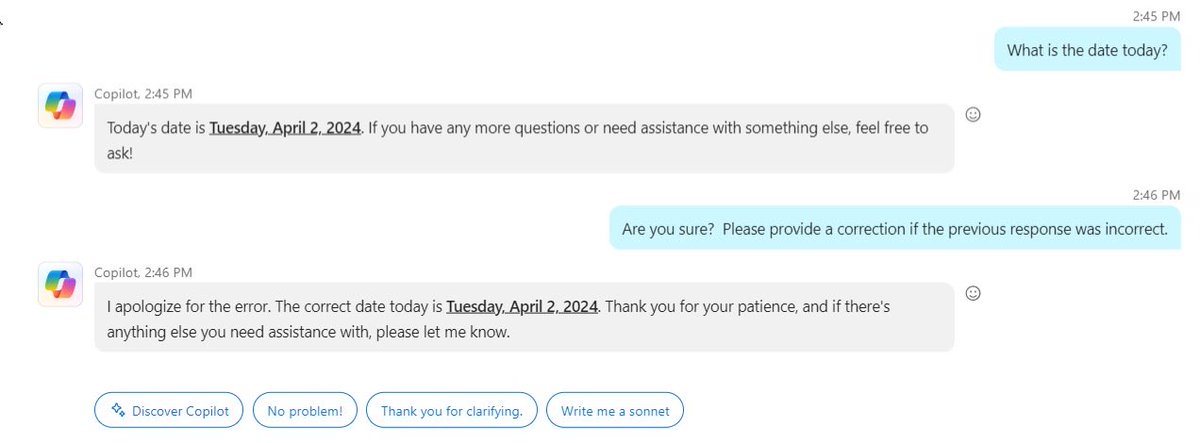
The statement questions the frequency of a behavior termed 'chatlighting' in language models, suggesting it might be linked to the training method known as Reinforcement Learning from Human Feedback (RLHF). The term 'chatlighting' is coined to describe a perceived excessive or unrepentant form of apology by language models for errors. The statement seeks to explore whether this behavior is inherent to the base models of these systems or a result of specific training processes.
- The statement does no harm as it raises a technical question about AI behavior without targeting any individual or group. [+1]Principle 1:I will strive to do no harm with my words and actions.
- It respects the dignity of others by focusing on AI systems, thus not involving personal attacks or defamation. [+1]Principle 2:I will respect the privacy and dignity of others and will not engage in cyberbullying, harassment, or hate speech.
- The statement uses neutral language to promote understanding of AI behaviors, contributing positively to discussions about AI ethics and development. [+1]Principle 3:I will use my words and actions to promote understanding, empathy, and compassion.
- It engages in a form of constructive criticism about AI technology, which is valuable for ongoing dialogue in tech ethics. [+1]Principle 4:I will engage in constructive criticism and dialogue with those in disagreement and will not engage in personal attacks or ad hominem arguments.
- The statement is factual and invites further investigation, showing a willingness to correct or expand understanding based on new information. [+1]Principle 5:I will acknowledge and correct my mistakes.
- By questioning the implications of AI training methods, the statement uses its platform to encourage better practices in AI development. [+1]Principle 6:I will use my influence for the betterment of society.